Introduction
I spend a lot of time on YouTube. Between vlogs, science channels, computer science tutorials, and video essays I have spent countless hours on the platform. As with anything I spend so much time on, I find it fun to look through exactly how I spend it. With Google Takeout and the YouTube API, analyzing your personal YouTube history isn’t too difficult.
Gather the Data
YouTube History is all available through Google Takeout. Toggle YouTube data and select the fields you want. The only archive I’ll be looking into is the “history” data. You may have multiple accounts with different data under each one so be sure go through each account you use to watch YouTube videos and create an archive. If you have uploaded any videos, I recommend you make sure to click the options and uncheck videos from your archive. Exporting your videos will take a lot of time and the archive will be much larger.
Format the Data
YouTube History is formatted a bit oddly. Currently it can only be exported as HTML. We’ll be using the rvest library to parse HTML into a tidy dataframe.
First, include all the libraries.
library(rvest) # parse html
library(stringr) #string functions
library(jsonlite) # parse json
library(tidyverse) # make R fun
library(lubridate) # parse dates
library(tidytext) # text functions
library(httr) # api requestsyoutube.search.history <- read_html("../data/YouTubeAccount/Takeout/YouTube/history/search-history.html")To parse out text in HTML using the rvest package, you can specify CSS classes that denote a region. ".header-cell + .content-cell > a" looks for the hyperlink in the first content-cell. Parsing HTML can be tricky if you don’t have much experience with front-end web development. However, there are chrome add-ons, which can highlight similar regions and give you the necessary CSS classes to find every instance of the item.
youtube.search <- youtube.search.history %>%
html_nodes(".header-cell + .content-cell > a") %>%
html_text()You can get the timestamp in the same way.
youtube.search.content <- youtube.search.history %>%
html_nodes(".header-cell + .content-cell")
youtube.search.time.string <- str_match(youtube.search.content, "<br>(.*?)</div>")[,2]
youtube.search.time <- mdy_hms(youtube.search.time.string)Now that we have our search and timestamp, we can put them into a dataframe. If the count in each list doesn’t match, you’ll get an error at this step. That means that your parsing missed some records.
youtube.search.df <- data.frame(search = youtube.search,
time = youtube.search.time,
stringsAsFactors = FALSE)head(youtube.search.df)## search time
## 1 biomutant gameplay 2018-11-13 18:29:21
## 2 elder scrolls 6 2018-11-13 18:28:58
## 3 best indie games 2018 2018-11-13 18:19:51
## 4 west of loathing 2018-11-13 18:13:07
## 5 top indie games of 2018 2018-11-13 17:47:58
## 6 date night 2018-11-04 18:15:55Watch History
Watch history is stored in a separate HTML file. Parsing is very similar; it just requires a little more pattern matching.
First, read the HTML file.
watch.history <- read_html("../data/YouTubeAccount/Takeout/YouTube/history/watch-history.html")Each entry is within a content-cell, same as search history.
watched.video.content <- watch.history %>%
html_nodes(".header-cell + .content-cell") Create Data Frame
We’ll need to parse out this information with regex. If you’re not sure what regex is here is a tutorial by Jonny Fox. I highly recommend testing and playing with regex on regexr.com. If you want different information or Google decides to change how they format their archives, these will have to be changed.
#Grabs possible time characters between html <br> and </div> tags
watch.video.times <- str_match(watched.video.content, "<br>([A-Z].*)</div>")[,2]
#All possible id values after the url 'watch' parameter
watched.video.ids <- str_match(watched.video.content, "watch\\?v=([a-zA-Z0-9-_]*)")[,2]
#Grab the video title text after the id
watched.video.titles <- str_match(watched.video.content, "watch\\?v=[a-zA-Z0-9-_]*\">(.*?)</a>")[,2]Now we can join all of this back into a dataframe.
watched.videos.df <- data.frame(id = watched.video.ids, scrapedTitle = watched.video.titles, scrapedTime = watch.video.times, stringsAsFactors = FALSE)watched.videos.df$time <- mdy_hms(watched.videos.df$scrapedTime)head(watched.videos.df)## id
## 1 SZQz9tkEHIg
## 2 -24fSZ9l4Tc
## 3 4gCAeDu5Ziw
## 4 xb6RYAr0Wuw
## 5 iVWOZ8ctPE0
## 6 5H9IWS3YULw
## scrapedTitle
## 1 Hacker Breaks Down 26 Hacking Scenes From Movies & TV | WIRED
## 2 15 Minutes of New Biomutant Gameplay - Gamescom 2018
## 3 TOP 20 Most Anticipated Games of 2019 | PS4 Xbox One PC
## 4 Top 10 NEW November Indie Games of 2018
## 5 FUNNIEST GAME EVER | West of Loathing - Part 1
## 6 Indie Game of the Year 2017 - Top 10 Countdown
## scrapedTime time
## 1 Nov 13, 2018, 6:30:13 PM EST 2018-11-13 18:30:13
## 2 Nov 13, 2018, 6:29:24 PM EST 2018-11-13 18:29:24
## 3 Nov 13, 2018, 6:23:35 PM EST 2018-11-13 18:23:35
## 4 Nov 13, 2018, 6:21:00 PM EST 2018-11-13 18:21:00
## 5 Nov 13, 2018, 6:13:10 PM EST 2018-11-13 18:13:10
## 6 Nov 13, 2018, 5:55:06 PM EST 2018-11-13 17:55:06Video Metadata
The really interesting stuff comes when you integrate with the YouTube API to get metadata. Instead of only seeing the title, channel, and timestamp, you can get any information about the video or channel that you watched. This way you can see the popularity, descriptions, categories, and more of the videos you watch. Luckily, the API defaults to a limit of up to 1 million requests per day. Some requests count as more than others, but if you’re only getting metadata you should be using just a few requests units per query. There is an additional limitation of 300,000 request per second per user.
Youtube API Setup
https://developers.Google.com/YouTube/v3/getting-started
Follow the steps at the top to get credentials. Once you make a Google project (I titled mine “Analytics”), enable the YouTube Data API v3 and find the credentials from the sidebar menu.
https://developers.Google.com/YouTube/v3/getting-started#calculating-quota-usage
youtube.api.key <- "[Enter your key here]"From here you can use that API in a query similar to how I showed in How to Download and Analyze Your RescueTime Data in R.
connection.url <- 'https://www.googleapis.com/youtube/v3/videos'
video.id <- "BcXAxiRDOiA"
query.params <- list()
query.response <- GET(connection.url,
query = list(
key = youtube.api.key,
id = video.id,
fields = "items(id,snippet(channelId,title,categoryId))",
part = "snippet"
))
parsed.data <- content(query.response, "parsed")parsed.data <- readRDS("../data/parsed_metadata_example.rds")str(parsed.data)## List of 1
## $ items:List of 1
## ..$ :List of 2
## .. ..$ id : chr "BcXAxiRDOiA"
## .. ..$ snippet:List of 3
## .. .. ..$ channelId : chr "UCtnX-DOfwbClk-bAGc7w3lA"
## .. .. ..$ title : chr "Tuition Takes Flight"
## .. .. ..$ categoryId: chr "23"A couple key components here are the fields and part parameters. The part parameter filters down your query into subsets of data. It is important to specify only the parts you need because the fewer parts you request, the more queries you will be able to run. The fields parameter specifies fields within the part. The fields do not impact your request quota, but it will impact bandwidth as more fields will take more time to send over the internet.
Here are all the parts available to query. You can find more information in the YouTube documentation.
- snippet
- contentDetails
- fileDetails
- player
- processingDetails
- recordingDetails
- statistics
- status
- suggestions
- topicDetails
Getting Video Category
To get metadata for a video we can use the video ids we parsed out of our HTML archive and make requests to YouTube for more information about each video.
Prepare Requests
Since we’re about to make several thousand requests to the YouTube API (one for every video watched) and make a dataframe out of the responses, there is some extra preparation to do.
Speeding up the requests
There are a few libraries that allow you to make requests over the web. httr is probably the most common, but there are also RCurl and curl. httr only supports one request at a time, so will likely be much slower. To make sure we can get this data as fast as possible, I tested all three.
I’ll use Google to test the APIs.
test.connection <- "https://www.google.com"
test.count <- 100httr Speed Test
system.time(for(i in 1:test.count){ result <- GET(test.connection)})RCurl Speed Test
library(RCurl)uris = rep(test.connection, test.count)
system.time(txt <- getURIAsynchronous(uris))curl Speed Test
library(curl)pool <- new_pool()
for(i in 1:test.count){curl_fetch_multi(test.connection)}
system.time(out <- multi_run(pool = pool))I also tested a lower-level implementation of curl. It appears to be slower, but here it is in case you were curious.
cb <- function(req){.GlobalEnv$test.count <-.GlobalEnv$test.count + 1}
handles = list()
for(i in 1:test.count){handles <<- append(handles,new_handle(url = 'https://www.google.com'))}
for(i in 1:test.count){multi_add(handles[[i]])}
system.time(test.out <- multi_run())Test them all out for yourself. The speed may differ based on your settings and queries.
Formatting the Requests
With curl we don’t have the nice syntax of an httr GET request. We will need to create the full connection string for each request. Edit the fields and snippet parameter for the information you want.
create.request <- function(id){
paste0(connection.url,
"?key=",youtube.api.key,
"&id=",id,
"&fields=","items(id,snippet(channelId,title,description,categoryId))",
"&part=","snippet")
}Remove duplicates to reduce the number of requests you make.
unique.watched.video.ids <- unique(watched.videos.df$id)Since I’m using apply a lot on some long running operations, I started using the pbapply package to track progress for apply operations.
library("pbapply") # track progress on apply functionsCreate a list of request URLs.
requests <- pblapply(unique.watched.video.ids, create.request)We will also need a function to parse out our data from the curl response.
get.metadata.df <- function(response){
rawchar <- rawToChar(response$content)
parsed.data <- fromJSON(rawchar)
data.frame <- cbind(id = parsed.data$items$id, parsed.data$items$snippet)
return(data.frame)
}Async curl requests allow you to create functions for what to do when a request succeeds and what to do when it fails. We can set it up so that we automatically append our response dataframe whenever a request finishes.
video.metadata.dataframe <- data.frame(id = c(), channelId = c(), title = c(), description = c(), categoryId = c())
# Success Function
add.to.metadata.df <- function(response){
.GlobalEnv$video.metadata.dataframe <- rbind(.GlobalEnv$video.metadata.dataframe,get.metadata.df(response))
}
# Fail Function
fail.func <- function(request){
print("fail")
}However, since we’re having many asynchronous requests edit a single variable, it is possible that some data will be overwritten. A more reliable method to get your data is to grab it from your memory. However, this method will be slower.
# Grab a request response from memory
fetch.metadata.from.memory <- function(request){
return(get.metadata.df(curl_fetch_memory(request)))
}Now we can set up our multi request. The curl_fetch_multi command adds the requests to the pool, but doesn’t execute them.
To run the requests, use the multi_run command.
system.time(out <- multi_run(pool = pool)) #usually around 10 minutesSave the dataframe.
saveRDS(video.metadata.dataframe, file = "video_metadata_dataframe_async.rds")If you notice the counts are different from unique requests to the metadata dataframe, you may want to generate the metadata from memory. If they are the same, you can skip this step to save some computation time.
length(requests)## [1] 12581nrow(video.metadata.dataframe)## [1] 11993To pull from memory, run the fetch.metadata.from.memory function over your requests.
list.metadata <- pblapply(requests, fetch.metadata.from.memory)Use bind_rows to combine the list into a tidy dataframe.
video.metadata.dataframe <- bind_rows(list.metadata)saveRDS(video.metadata.dataframe, file = "video_metadata_dataframe_memory.rds")Format Categories
Categories are returned as an id. I’d prefer to have them in text form. To get the list of names, we’ll need to make another request.
category.list.url <- "https://www.googleapis.com/youtube/v3/videoCategories"
category.response <- GET(url = category.list.url,
query = list(
key = youtube.api.key,
regionCode = "us",
part = "snippet"
))
parsed.category.response <- content(category.response, "parsed")category.dataframe <- data.frame(categoryId=c(), category=c())
for( item in parsed.category.response$items){
category.dataframe <<-rbind(category.dataframe, data.frame(categoryId = item$id, category=item$snippet$title))
}category.dataframe## categoryId category
## 1 1 Film & Animation
## 2 2 Autos & Vehicles
## 3 10 Music
## 4 15 Pets & Animals
## 5 17 Sports
## 6 18 Short Movies
## 7 19 Travel & Events
## 8 20 Gaming
## 9 21 Videoblogging
## 10 22 People & Blogs
## 11 23 Comedy
## 12 24 Entertainment
## 13 25 News & Politics
## 14 26 Howto & Style
## 15 27 Education
## 16 28 Science & Technology
## 17 29 Nonprofits & Activism
## 18 30 Movies
## 19 31 Anime/Animation
## 20 32 Action/Adventure
## 21 33 Classics
## 22 34 Comedy
## 23 35 Documentary
## 24 36 Drama
## 25 37 Family
## 26 38 Foreign
## 27 39 Horror
## 28 40 Sci-Fi/Fantasy
## 29 41 Thriller
## 30 42 Shorts
## 31 43 Shows
## 32 44 TrailersMerge the dataframes to add the new column.
video.metadata <- merge(x = video.metadata.dataframe, y = category.dataframe, by = "categoryId")head(video.metadata)## categoryId id channelId
## 1 1 QUlr8Am4zQ0 UCtlp8d4cZg2eMrVbq7vxg9w
## 2 1 hkLNW38OVNo UCYo4DGKIw8UmIQXbTuP3JsQ
## 3 1 anndNbRjOeE UCx0L2ZdYfiq-tsAXb8IXpQg
## 4 1 8mFsbfuNrzQ UCdRcrkWSxxGJJ5va0n6hX6A
## 5 1 0bfAwn70NZc UC6MFZAOHXlKK1FI7V0XQVeA
## 6 1 PgCn-3eY6ms UCOP-gP2WgKUKfFBMnkR3iaA
## title
## 1 The Circle | Official Trailer | Own it Now on Digital HD, Blu-rayâ„¢ & DVD
## 2 Fisheye
## 3 Black Panther Fixes Marvel's Most Common Flaws
## 4 Osteen's Day Off
## 5 Nailing every high note in Take On Me
## 6 Appropriate Behavior Official Trailer 1 (2015) - Comedy Movie HD
## description
## 1 The Circle is a gripping modern thriller, set in the not-too-distant future, starring Emma Watson (“Harry Potterâ€), Tom Hanks (“Sullyâ€) and John Boyega (“Star Wars: The Force Awakensâ€).\n \nWhen Mae (Emma Watson) is hired to work for the world’s largest and most powerful tech & social media company, she sees it as an opportunity of a lifetime. As she rises through the ranks, she is encouraged by the company’s founder, Eamon Bailey (Tom Hanks), to engage in a groundbreaking experiment that pushes the boundaries of privacy, ethics and ultimately her personal freedom. Her participation in the experiment, and every decision she makes begin to affect the lives and future of her friends, family and that of humanity.\n\nOwn it Now on Digital HD, Blu-rayâ„¢ & DVD\n\nSUBSCRIBE: http://stxent.co/Subscribe\n\nConnect with The Circle:\nWEBSITE: http://thecircle.movie/\nFACEBOOK: https://www.facebook.com/WeAreTheCircle/\nTWITTER: https://twitter.com/WeAreTheCircle\nINSTAGRAM: https://www.instagram.com/wearethecircle/\n#TheCircle\n\nSTX Entertainment\nSTX Entertainment is a fully integrated, diversified, global media company designed from inception to unlock value from the 21st Century’s changed media landscape. STX specializes in the development, production, marketing and distribution of talent-driven films, television, and digital media content, with a unique ability to maximize the impact of content across worldwide, multiplatform distribution channels, including unparalleled global capabilities and direct passage into the China market.\n\nConnect with STX Entertainment Online:\nWEBSITE: http://stxent.co/Website\nFACEBOOK: http://stxent.co/Facebook\nTWITTER: http://stxent.co/Twitter\n\nThe Circle | Official Trailer | Own it Now on Digital HD, Blu-rayâ„¢ & DVD https://www.youtube.com/STXentertainment
## 2 A serious short film by Rocco Botte
## 3 For 10% off your first purchase, go to http://www.squarespace.com/justwrite\nHelp me make more videos about storytelling by clicking here: https://www.patreon.com/justwrite\n\nThere are a handful of common criticisms that apply to almost every film made by Marvel Studios, from unmemorable music, to ugly color grading, and generic villains. But Black Panther is different. In this video, I look at how the film solves a lot of Marvel’s most common storytelling problems, as well as some of the techniques Ryan Coogler uses to tell a story that resonates.\n\nJoin the community!\nWebsite â–¶ https://www.justwritemedia.com\nTwitter â–¶ https://www.twitter.com/SageHyden\nFacebook â–¶ http://www.facebook.com/justwriteyoutube\n\nArt by Guile Sharp and Mark H. Roberts.\n\nMy original video on Bathos, “What Writers Should Learn From Wonder Woman.â€\nhttps://www.youtube.com/watch?v=w-QhdzQo66o&t=135s\n\nMy video on what makes the villains in The Legend Of Korra special: \nhttps://www.youtube.com/watch?v=uiGQGmnMt0I&t=204s\n\nCitations:\n\nEvery Frame A Painting, “The Marvel Symphonic Universe.â€\nhttps://www.youtube.com/watch?v=7vfqkvwW2fs\n\nPatrick (H) Willems, “Why Do Marvel’s Movies Look King Of Ugly? (video essay)â€\nhttps://www.youtube.com/watch?v=hpWYtXtmEFQ\n\nVOX article:\nhttps://www.vox.com/culture/2017/11/8/16559940/thor-ragnarok-villain-hela-problem\n\nGeeks article: \nhttps://geeks.media/marvel-has-a-problem-creating-villains-in-the-mcu\n\nCinemaBlend article: \nhttps://www.cinemablend.com/new/Reason-Marvel-Villains-Disappointing-According-Civil-War-Writer-128947.html\n\nDigital Spy article: \nhttp://www.digitalspy.com/movies/the-avengers/feature/a800252/marvel-has-a-villain-problem-and-heres-how-to-fix-it/\n\nMusic: \n\n“Electric Mantis - Daybreak | Majestic Colorâ€\nhttp://ow.ly/G7gg30iypqm\n\n“I’m Going For A Coffee,†by Lee Rosevere, Music For Podcasts 3\nhttp://ow.ly/yFpc30iyptv
## 4 Joel lets loose after the Sabbath. Osteen fanatics better buckle up for this inside look into Joel's very rare day off.\n\nDirected by David Michor
## 5 truly i am a master of singing\n\nMy Twitter: https://twitter.com/prozdkp\nMy Let's Play channel, Press Buttons n Talk:\nhttps://www.youtube.com/channel/UCSHsNH4FZXFeSQMJ56AdrBA\nMy Merch/T-Shirt Store: http://www.theyetee.com/prozd\nMy Tumblr: http://prozdvoices.tumblr.com/\nMy Twitch: https://www.twitch.tv/prozd\nMy Instagram: https://instagram.com/prozd\nMy Patreon: http://www.patreon.com/prozd\nUse the link below and the coupon code ProZDCrate to get 10% off any Loot Crate:\nhttps://lootcrate.com/ProZD\nUse the link below and the coupon code PROZDSNACKS to get $3 off your first Japan Crate Premium or Original:\nhttp://japancrate.com/?tap_a=13976-19476b&tap_s=76467-12d24b\nUse the link below and the coupon code PROZDRAMEN to get $3 off your first Umai Crate:\nhttp://japancrate.com/umai?tap_a=18655-b8af8b&tap_s=76467-12d24b\nUse the link below to get a free 14-day trial of Funimation anime streaming:\nhttps://www.funimation.com/prozd\nUse the link below and coupon code PROZD10 to get $10 off any Classic Bokksu subscription:\nhttp://www.bokksu.com?rfsn=498614.9d328&utm_source=refersion&utm_medium=influencers&utm_campaign=498614.9d328\nUse the link below and coupon code PROZD to get $3 off your first Tokyo Treat premium box, YumeTwins box, or nmnl box:\nhttps://tokyotreat.refersion.com/c/2b878
## 6 ► Download App (iOS): http://goo.gl/WGPXM6\n► Download App (Android): http://goo.gl/7h3zLI\n► Click to Subscribe: http://goo.gl/HNyuHY\n\nShirin is struggling to become an ideal Persian daughter, politically correct bisexual and hip young Brooklynite but fails miserably in her attempt at all identities. Being without a cliché to hold onto can be a lonely experience.\n\nRelease Date: 16 January 2015\nDirector: Desiree Akhavan\nCast: Desiree Akhavan, Rebecca Henderson, Scott Adsit\nGenre: Comedy\nCountry: UK\nProduction Co: Parkville Pictures\nDistributor: Gravitas Ventures (USA)\n\nFilmIsNow your first stop for the latest new cinematic videos the moment they are released. Whether it is the latest studio trailer release, an evocative documentary, clips, TV spots, or other extra videos, the FilmIsNow team is dedicated to providing you with all the best new videos because just like you we are big movie fans.\n\nSubscribe: http://goo.gl/8WxGeD\nG+ Page: http://goo.gl/Slx3tQ\nWebsite: http://www.filmisnow.com\nFacebook: http://on.fb.me/UFZaEu\nTwitter: http://twitter.com/#!/filmisnow
## category
## 1 Film & Animation
## 2 Film & Animation
## 3 Film & Animation
## 4 Film & Animation
## 5 Film & Animation
## 6 Film & AnimationCombine with Watch History
We can combine the new dataframe with our watch history to get the metadata of a video along with when we watched it.
watched.videos <- merge(watched.videos.df , video.metadata, by="id")watched.videos <- readRDS(file="../data/watched_videos_final.rds")str(watched.videos)## 'data.frame': 12960 obs. of 9 variables:
## $ id : chr "--aFqzM7yxw" "--v7Uzmn37c" "-_8MtJ6WujI" "-_KPiF8_njE" ...
## $ scrapedTitle: chr "How To Prepare A Best Man Speech" "Emotiv Insight Black Unboxing + Kickstarter T-Shirt & Badge" "Parrot MiniDrone Jumping Sumo official video" "The Pyramid Drinking Game" ...
## $ scrapedTime : chr "Jul 8, 2018, 12:22:11 PM EST" "Feb 7, 2018, 12:34:48 PM EST" "Mar 29, 2015, 8:57:44 AM EST" "Sep 21, 2018, 7:00:18 PM EST" ...
## $ time : POSIXct, format: "2018-07-08 12:22:11" "2018-02-07 12:34:48" ...
## $ categoryId : chr "26" "28" "24" "24" ...
## $ channelId : chr "UCjHm4Br34sBmjbBdA0TQH-Q" "UCdnQWZjcq392Ojp9C0v1-Rg" "UC8F2tpERSe3I8ZpdR4V8ung" "UC1_6Ox4UVx2mVPq52u8x3gg" ...
## $ title : chr "How To Prepare A Best Man Speech" "Emotiv Insight Black Unboxing + Kickstarter T-Shirt & Badge" "Parrot MiniDrone Jumping Sumo official video" "The Pyramid Drinking Game" ...
## $ description : chr "This tutorial is a practical time-saver that will enable you to get good at speeches. Watch our short video on "| __truncated__ "The Emotiv Insight Black Edition Unboxing + Kickstarter T-Shirt & Badge" "Purchase a Jumping Sumo : https://www.parrot.com/us/minidrones/parrot-jumping-sumo#parrot-jumping-sumo-details\"| __truncated__ "A how-to-play video for the pyramid drinking game\nAlso as an exercise for after effect.\nBGM: Session 004 - Ch"| __truncated__ ...
## $ category : Factor w/ 31 levels "Film & Animation",..: 14 16 12 12 12 7 14 14 14 11 ...Analysis
With search history, watch history, and video metadata we can start to do analysis.
What categories of videos do I watch?
watched.videos %>% group_by(category) %>% summarise(count = n()) %>% arrange(desc(count))## # A tibble: 18 x 2
## category count
## <fct> <int>
## 1 Entertainment 1948
## 2 Education 1842
## 3 Gaming 1660
## 4 Comedy 1337
## 5 People & Blogs 1315
## 6 Music 1242
## 7 Science & Technology 1068
## 8 Film & Animation 877
## 9 News & Politics 618
## 10 Howto & Style 460
## 11 Pets & Animals 180
## 12 Sports 106
## 13 Nonprofits & Activism 93
## 14 Travel & Events 81
## 15 Autos & Vehicles 71
## 16 Shows 52
## 17 Trailers 9
## 18 Movies 1Has my genre taste changed over time?
watched.videos %>% ggplot(aes(x = time, fill = category)) + geom_area(stat = "bin")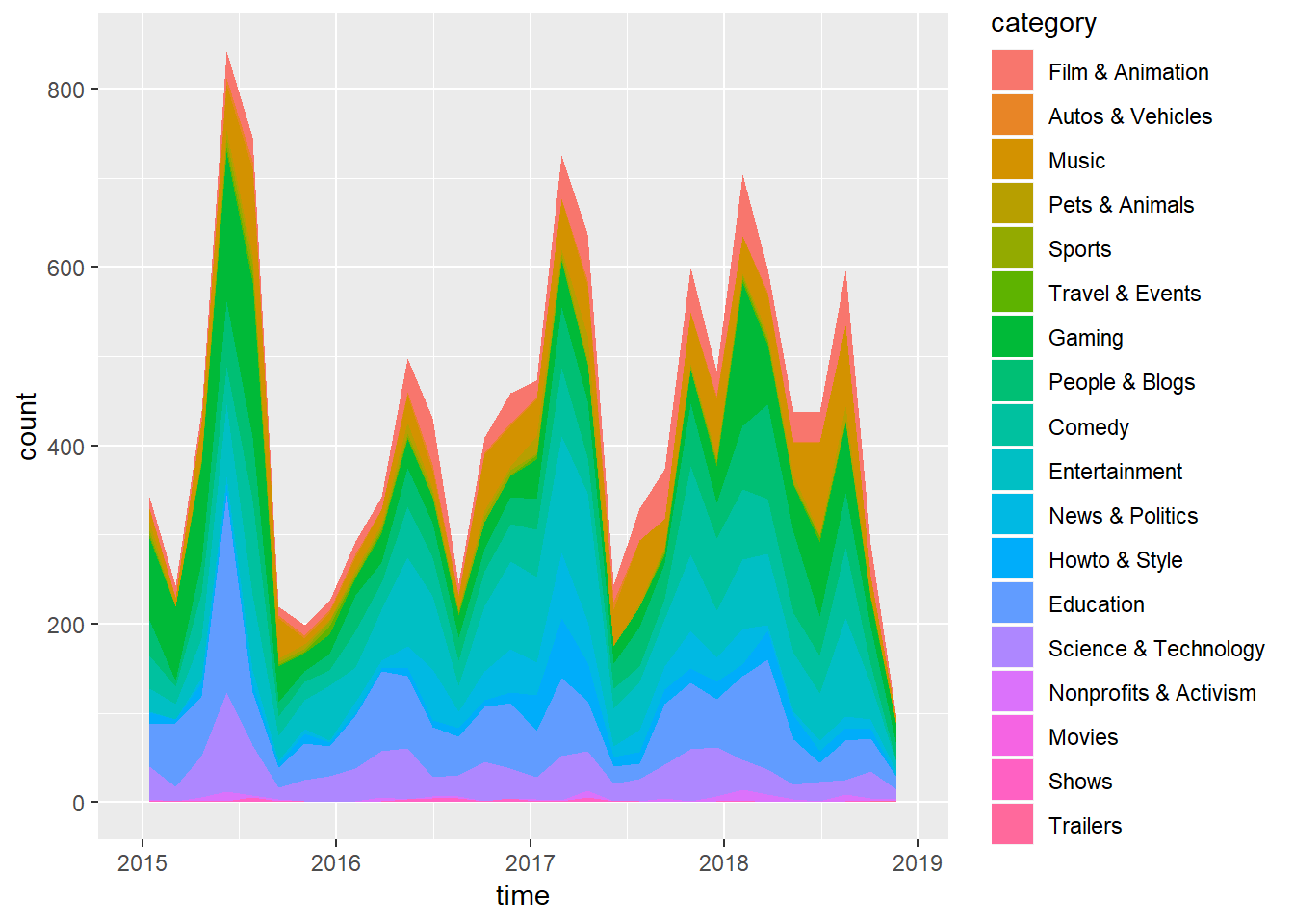 The peaks are interesting, but I don’t see much divergence in the category of videos that I have watched over time.
The peaks are interesting, but I don’t see much divergence in the category of videos that I have watched over time.
Watches Per Hour of Day
What time of day do I usually watch YouTube Videos? I’m going to try out a clock plot from here. I just copied and pasted the code from the gallery.
clock.plot <- function (x, col = rainbow(n), ...) {
if( min(x)<0 ) x <- x - min(x)
if( max(x)>1 ) x <- x/max(x)
n <- length(x)
if(is.null(names(x))) names(x) <- 0:(n-1)
m <- 1.05
plot(0, type = 'n', xlim = c(-m,m), ylim = c(-m,m), axes = F, xlab = '', ylab = '', ...)
a <- pi/2 - 2*pi/200*0:200
polygon( cos(a), sin(a) )
v <- .02
a <- pi/2 - 2*pi/n*0:n
segments( (1+v)*cos(a), (1+v)*sin(a), (1-v)*cos(a), (1-v)*sin(a) )
segments( cos(a), sin(a),0, 0, col = 'light grey', lty = 3)
ca <- -2*pi/n*(0:50)/50
for (i in 1:n) {
a <- pi/2 - 2*pi/n*(i-1)
b <- pi/2 - 2*pi/n*i
polygon( c(0, x[i]*cos(a+ca), 0), c(0, x[i]*sin(a+ca), 0), col=col[i] )
v <- .1
text((1+v)*cos(a), (1+v)*sin(a), names(x)[i])
}
}clock.df <- watched.videos %>% mutate(hour = hour(time)) %>% group_by(hour) %>% summarise(count = n()) %>% arrange(hour)
clock.plot(clock.df$count, main = "Watches per hour of the day")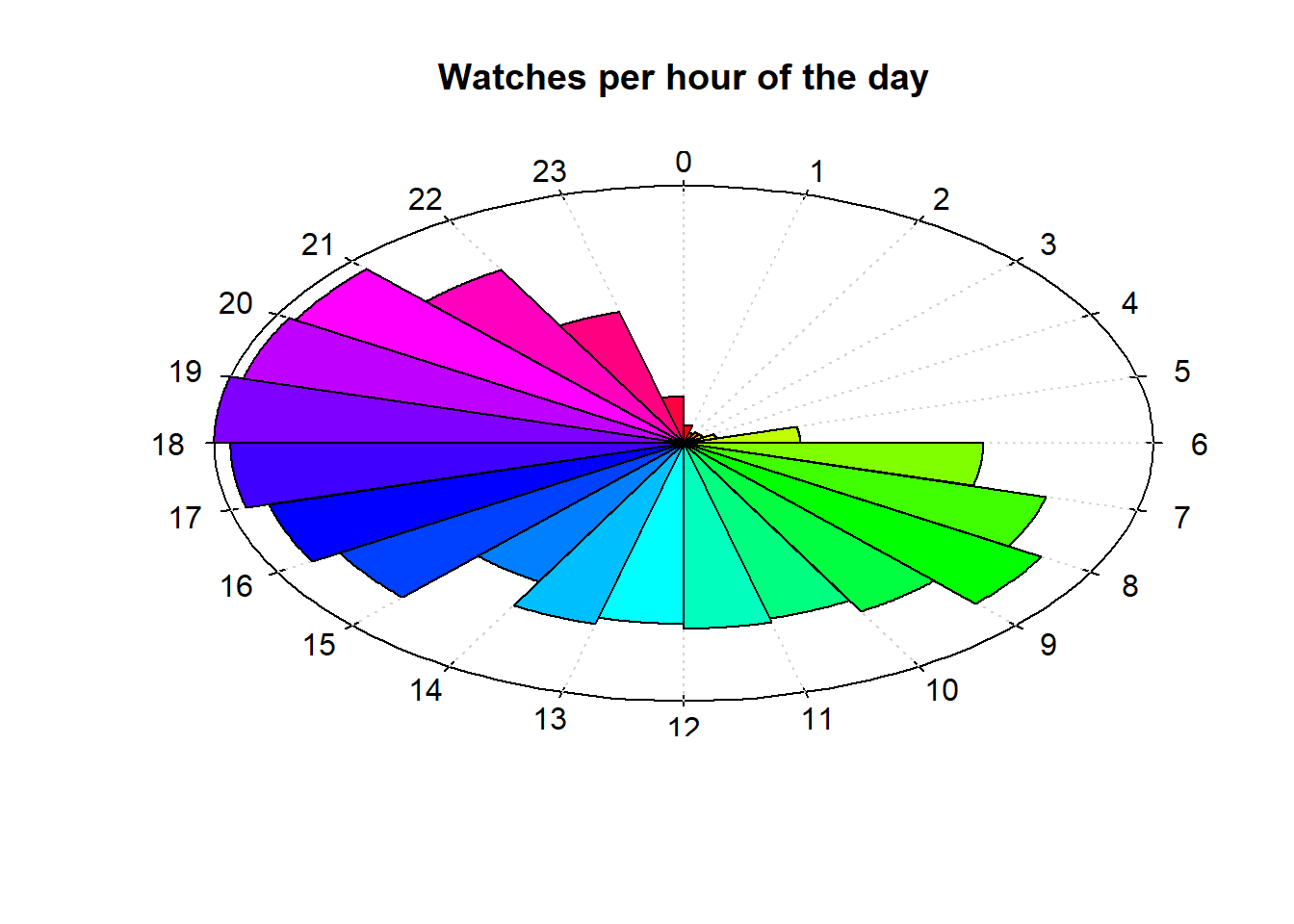
I’m honestly surprised by how much I was able to watch videos between 6AM and 5PM. I suppose that is the benefit of college.
Most Re-Watched Videos
It’s simple enough to find the most re-watched videos per year
watched.videos %>% mutate(year = year(time)) %>% group_by(year, title) %>% summarise(count = n()) %>% arrange(year, desc(count)) %>% top_n(5)## # A tibble: 29 x 3
## # Groups: year [4]
## year title count
## <dbl> <chr> <int>
## 1 2015 4 Chords | Music Videos | The Axis Of Awesome 4
## 2 2015 Dark Souls 2 Walkthrough - BEST POSSIBLE START 4
## 3 2015 Kid Cudi - Cudderisback (Official Music Video) 4
## 4 2015 Moonmen Music Video (Complete) feat. Fart and Morty | Rick~ 4
## 5 2015 Speedrunning - Games Done Quick and Developer Tips - Extra~ 4
## 6 2016 history of japan 4
## 7 2016 Agony | Into the woods 2014 | Chris Pine & Billy Magnussen 3
## 8 2016 How to Use SPSS: Intra Class Correlation Coefficient 3
## 9 2016 Kid Cudi - All Summer [ Music Video ] 3
## 10 2016 Rihanna's 'Work' Is Not Tropical House 3
## # ... with 19 more rowsI se a lot of my favorites, but also some surprises. I’d be interested in seeing watch time, as I’m pretty sure some of these I simply started a few times and only finished once. If anyone finds a way to access that information, please let me know.
Most Searched Terms
What terms did I search for the most?
words <- youtube.search.df %>%
unnest_tokens(word, search) %>%
anti_join(stop_words) %>%
count(word, sort = TRUE)library(wordcloud)# Image wordcloud
library(wordcloud2) # HTML wordcloud
wordcloud.text <- words %>%
group_by(word) %>%
summarize(count = sum(n)) %>%
anti_join(stop_words)
wordcloud(words = wordcloud.text$word, freq = wordcloud.text$count, min.freq = 20,
max.words = 72, random.order =FALSE, rot.per =.35,
colors=brewer.pal(8, "Dark2"))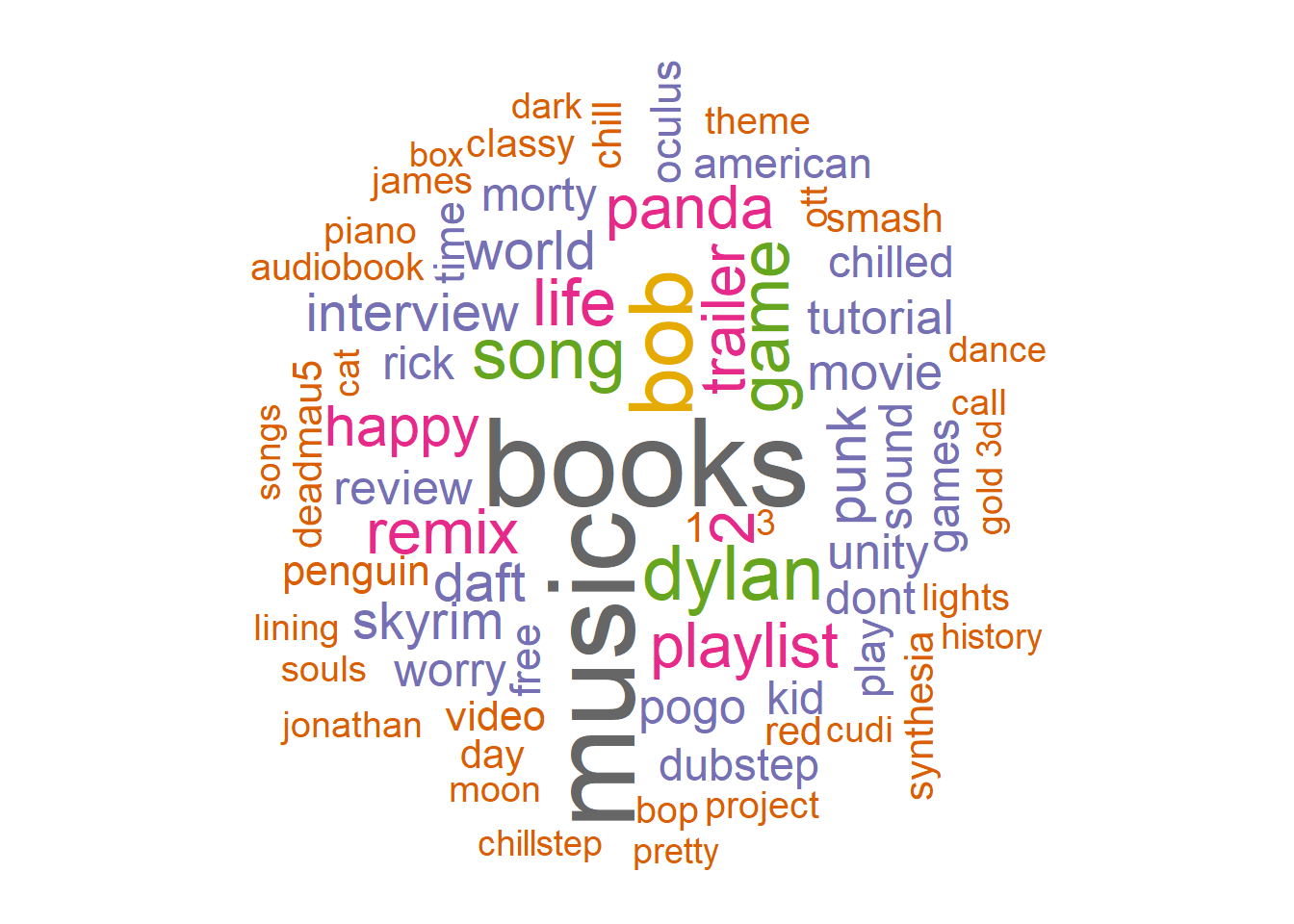
My search history goes all the way back to 2011, when I was 15. I guess I mostly search for music, with The Books being my favorite artist.
We can do the same thing for video descriptions to see the most common terms within the videos I watched.
description.wordcloud <- watched.videos %>%
unnest_tokens(word, description) %>%
anti_join(stop_words) %>%
count(word, sort = TRUE) %>%
filter(! word %in% c("http", "https", "bit.ly" , "â", "www.youtube.com")) %>%
filter(n > 300)
wordcloud2(description.wordcloud)There are an awful lot of references to other social media. Perhaps we need a specific stop words dictionary for YouTube/ social media. However, if you are doing any other text analysis you can filter these out with tf_idf.
There is plenty more to look at, and I hope to experiment more with my YouTube data in the future. I hope this helps you start exploring your own YouTube data.